은행마케팅 20대 고객 탐색적 데이터 분석
혼자 푼거라 깔끔하지 않고 에러가 뜰수도 있는 등 정답이 아님을 명시...!!!
#education-교육(unknown-모름 / secondary-중등교육의 / primary-초등교육의 / tertiary-고등교육의 )
#default- 신용 여부(yes / no )
#balance-유로의 연간평균수지 (-1137 ~ 64343)
#housing-주택융자 유무( yes / no)
#loan-개인융자 유무(yes / no)
#contact-연락수단? (unknown-모름 / telephone-유선전화 / cellular-무선전화)
#day of week- 이 달의 마지막 연락한 날 "fri" ~ "wed"
#month- 연 도의 마지막 접촉한 월 (1월, 2월 3월...) "apr" ~ sep"
#duration-마지막 연락처 기간 (7 ~ 2062)
#campaign-이 캠페인과 이 클라이언트에 대해 수행된 연락처 수 1 ~ 29
#pdays-이전 캠페인에서 클라이언트가 마지막으로 연락한 후 경과한 일 수//-1은 클라이언트가 이전에
#연결되지 않았음을 의미합니다. 1 ~ 999
#previous-이 캠페인 이전 및 이 클라이언트에 대해 수행된 연락처 수 0 ~ 6
#poutcome-이전 마케팅 캠페인의 결과 (모름 / 그밖의다른거 / 실패 / 성공)
#y-고객이 정기예금에 가입했는가? (yes / no)
#20대와 30대까지의 연령대에 해당하는 고객들의 데이터를 추출하여 20~30대 데이터 위주로 분석.
bank <- read.csv("C:\\rstudy\\day8\\data\\Data\\bnk05.csv")
str(bank)
min(bank$month)
max(bank$month)
#20대와 30대의 연령대에 해당하는 고객
s.bank <- subset(bank, 20<=age & age<40)
View(s.bank)
#20대에 해당하는 고객들만 다시 구분
tw.bank <- subset(s.bank, age<30)
View(tw.bank)
#2.연령의 분포를 보여주는 플롯
hist(s.bank$age)
#duration의 분포를 보여주는 플롯
plot(s.bank$duration)
#연령과 잔고의 scatterplot
plot(s.bank$age, s.bank$balance)
#동일한 연령이 많이 존재하므로 jitter를 활용한 플롯 작성하고 point색을 반투명한 blue로
plot(jitter(s.bank$age), col = "lightblue")
#결혼상태별 고객 수 막대차트
barplot(table(tw.bank$marital), main = "20대의 결혼상태 분포")
#잔고와 duration간의 분포를 보여주는 scatterplot작성하고 선형회귀선 추가
m <- lm(s.bank$balance ~ s.bank$duration)
plot(s.bank$balance,s.bank$duration, abline(m, col = "red"))
#결혼상태가 single인 경우는 blue, 아니라면 반투명 red로 point 색상 변경
ggplot(s.bank, aes(x=balance, y=duration))+geom_point(aes(color =ifelse(marital == "single","blue","grey")))
#duration과 balance 각각에 대한 중위수를 기준으로 수직, 수평의 보조구분선을 추가
median(s.bank$balance)
ggplot(s.bank, aes(duration, balance))+geom_point()+geom_hline(yintercept=480)
median(s.bank$duration)
ggplot(s.bank, aes(duration, balance))+geom_point()+geom_vline(xintercept=184)
#개인대출여부 별 잔고분포를 boxplot을 사용하여 나타내라
boxplot(balance ~ loan,data=s.bank)
#직업별 잔고의 중위수를 집계산출하고 막대 플롯을 작성하라
med <- aggregate(s.bank$balance,by=list(s.bank$balance),FUN =median)
barplot(s.bank$job,med)
#직업이 학생이면 blue로 아니면 grey로 색상을 지정해라
ggplot(s.bank, aes(x=balance,y=duration))+geom_point(aes(color = ifelse(job == "student", "blue", "grey")))
#20대 전체의 잔고 중위수 값을 기준으로 수평 보조선을 추가하라
median(tw.bank$balance)
ggplot(tw.bank, aes(x=balance,y=duration))+geom_point(aes(color = ifelse(job == "student", "blue", "grey")))+geom_hline(yintercept=559.5)
#20대 직업별 고객 수 비율을 table명령을 활용하여 구하고
a <- table(tw.bank$job)
b <- table(bank$job)
c <- merge(a,b)
#두가지를 하나의 데이터프레임으로 결합해서 생성하라
a <- table(tw.bank$job)
b <- table(bank$job)
barplot(a,b)
--------시각화실패.
#30대 고객의 연력과 잔고 간 scatterplot과 20대에 대한 것을 각각의 플롯으로 비교해보여주는 한장의 그림을 작성하라
par(mfrow =c(1,2))
th.bank <- subset(s.bank, 30<=age)
plot(th.bank$age,th.bank$balance)
plot(tw.bank$age,tw.bank$balance)
웹스크래핑 개요
웹크롤링-포털 등에서 자동으로 웹사이트의 링크 정보를 수집하여 저장하는 기술
웹스크래핑-웹 사이트로부터 웹문서를 다운로드 받아 필요한 정보를 추출하는 기술
공공데이터포털의 목록 추출
- 웹페이지 URL설정
- 웹페이지 읽기(read_html())
- 목록 아이템 제목 추출(html_nodes())
- 목록 아이템 개요 추출(html_nodes())
- 데이터 정제(gsub())
- 데이터 출력(data.frame())
HTML은 현재 인터넷에서 가장 널리 사용하는 언어로 웹페이지의 레이아웃과 내용을 담고 있음.
<html>, <title>, <body>, <h1>, <p> 등 태그들의 중첩된 구조
각 태그는 < 로 시작하고 </ 로 닫힘
실제로 이러한 태그 이름은 임의로 지정할 수 없음
임의로 지정한 다른 태그를 임의로 포함할 수 없음
각각은 웹 브라우저에서 특정한 의미를 가짐
내부에 일부 태그를 포함하는 것을 허용하거나 어떤 태그도 허용하지 않을 수 있음
<html> 태그는 모든 HTML 의 루트 요소임
가장 일반적으로 < 와 < 를 포함
<head> 태그에는 일반적으로 제목 표시줄과 웹 브라우저 탭 , 웹 페이지의 기타
메타데이터에 표시되는 < 이 포함되어 있음
<body> 는 웹 페이지의 레이아웃과 내용을 결정하는 데 중요한 역할을 함
<table>태그는 행 단위 구조로 되어 있음
tr 은 테이블 행 , th 는 테이블 헤더 셀 , < 는 테이블 셀을 나타냄
<table>같은 HTML 요소에는 <table attr1="value1" attr2="value2"> 형식의
추가적인 속성이 있을 수 있음
속성은 임의로 정의할 수 없는 대신 표준에 따라 고유한 의미를 갖음
앞 코드에서 id 는 테이블의 식별자이며 , border 는 테두리 너비를 제어함
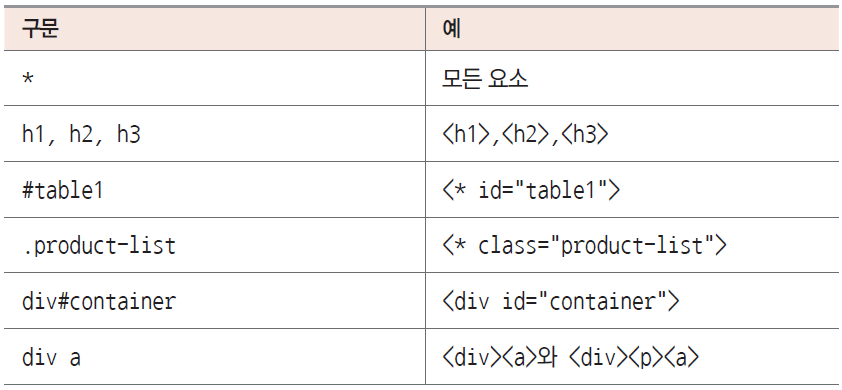
css선택자의 예

웹문서를 읽으려면 패키지를 로딩해야하는데
install.packages("rvest")
library(rvest)
read_html()함수로 웹문서 url을 읽어옴
데이터를 추출해야 하는 HTML 노드를 찾음
CSS 선택자나 XPath 표현식을 사용하여 HTML 노드를 필터링해서 필요한 노드를
선택함
필요하지 않은 노드는 생략함
노드의 부분 집합을 추출하는 데 html_nodes (), 속성을 추출하는 데 html_attrs (),
웹페이지에서 텍스트를 추출하는 데 html_text () 함수와 함께 적합한 선택자를 사용함
테이블 요소를 추출하려면 html_table()함수를 사용
gsub()함수로 띄어쓰기나 다른 특정문자가 들어있을 시에 공백으로바꿔주는등 깔끔하게 정리해주기
제대로 잘 작성한 HTML 문서는 기본적으로 특수한 버전의 XML( eXtensive Markup
Language) 문서라고 볼 수 있음
HTML 과 달리 XML 은 임의의 태그와 속성을 사용할 수 있음
XPath는 XML 문서에서 데이터를 추출하려고 설계한 기술임
html_node와 html_nodes () 함수는 xpath 인수로 XPath 표현식을 지원함
다음은중요한 CSS 선택자와 의미가 같은 XPath 표현식의 차이를 보여줌
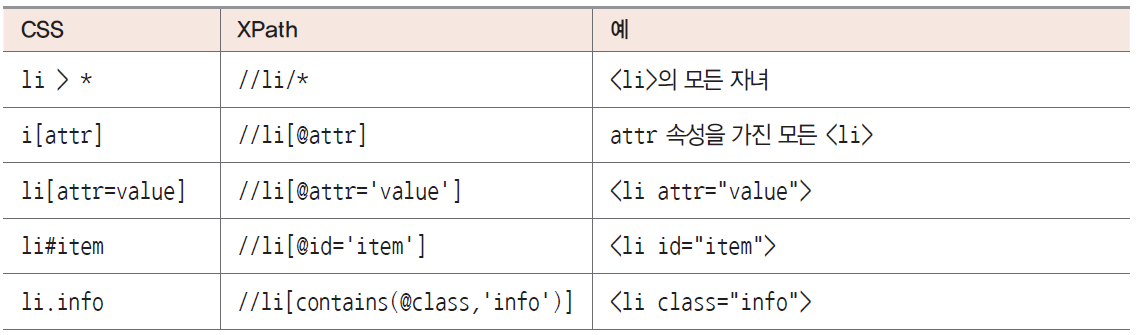
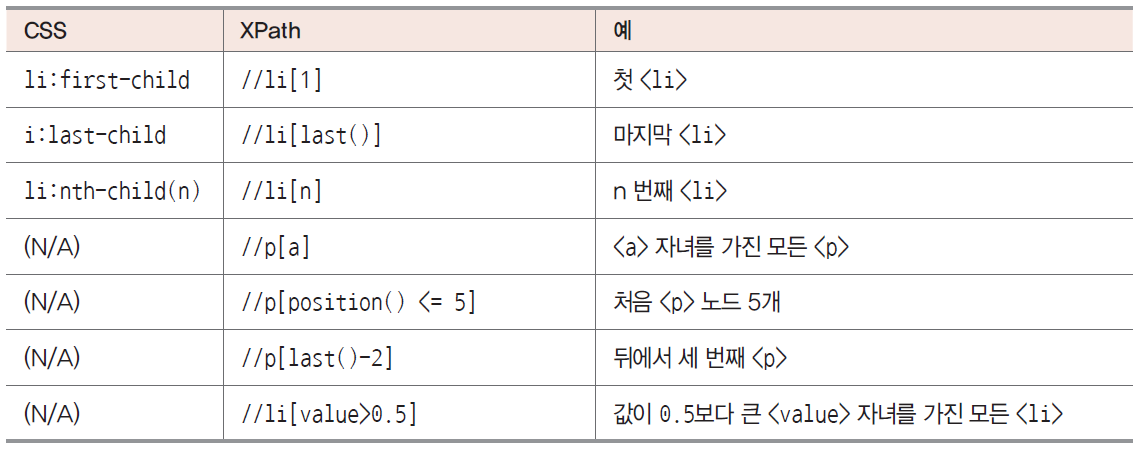
CSS 선택자는 일반적으로 모든 하위 수준의 노드와 일치함
XPath에서 와 / 태그는 노드를 서로 다르게 일치하도록 정의함
// 태그는 모든 하위 수준의 <tag> 노드를 나타냄
/ 태그는 첫 번째 하위 수준의 <tag> 노드만 나타냄
<head>
meta charset="utf-8"
<script></script>
<link ~~>
</head>
head사이에 들어감
<body>실제 우리가 볼수있는 화면을 만드는 코드가 들어감/아무거나 쓸 수 있음 아무리 띄어쓰기를 많이 해도 실제로 보이는건 한칸띄어쓰기로 보임 / 줄을 바꿔도 실제로 보이는건 줄이 바뀌지 않게보임/줄을 바꾸는 걸 출력하려면 <br/>을 사용.
단락을 만들어주는 태그 ->p테그, p테그가 막히면 줄이 바뀜<p> </p>
<table> 표 형태로 출력하게 해줌 id속성은 html을 조작할수있는 언어 자바스크립트
는 표두께
thead 강조하고 싶을 때
tbody는 데이터들을 출력할 때
<tr>행을 구성
한줄의 한칸을 만들어주는건 th(head쪽에서 사용), td(body쪽에서 사용)
</body>
<>한줄로 시작해서 닫아버리는 코드는 닫을 때 한칸 띄어야함
예: <img scr="~~~.jpg" />
<br> <br />
한줄로 끝나는 코드는 분리가 안되는것이기 때문에 그사이에 또다른 코드를 쓸 수 없음.
색깔 넣어주면서 꾸며주는 건 css
<head>
<style>코드는 바디 영역 쪽을 꾸며줌
h1{
color: darkblue;
} -> h1이라는 태그에다가 내부글씨색깔을 어두운 파란색으로 표현해라. 주로 제목을 표현할 때 사용: h1(가장 큰 글씨)~h6
.product-list {
width: 50px;
}
.product-list li.selected .name { -> .이 안붙은 li는 테그명임(h1도 마찬가지). product list를 찾고 그 중에서 li태그를 찾고 그 중에서 class값이 selected붙어있는 걸 찾고 그 내부에서 class속성값이 name을 갖고있는 걸 찾아라
color: blue;
}
#이 붙으면 해당 태그의 id 속성 // .이붙으면 클래스 속성값
div태그는 아무런 의미가 없는 영역만 잡아주는 태그
<div>
<ul> - 도형모양으로 목록을 만들어줌 , <ol> - abcd 나 1234 등으로 목록을 만들어줌
목록을 만들어주는 태그
- 자식태그는 <li>
<span> li내부글자들을 일괄적으로 속성을 바꿔줄때 범위잡아주는 것- css로 지정해줌
이건 한칸을 뜻함.
html은 mysql처럼 대소문자 구별안함
속성에 값을 넣을 경우 큰따옴표나 작은따옴표로 묶기
웹문서상은 모두 문자형.
node명은 태그
속성명은 html_attrs()
텍스트추출은 html_text()
html_table 테이블 요소 추출(특정요소)
html_node 특정 태그를 지정하는 방법
html_nodes와는 다름 : 클래스 속성값
single_table_page%>%html_node
*attr은 속성명을 쓰는 곳